

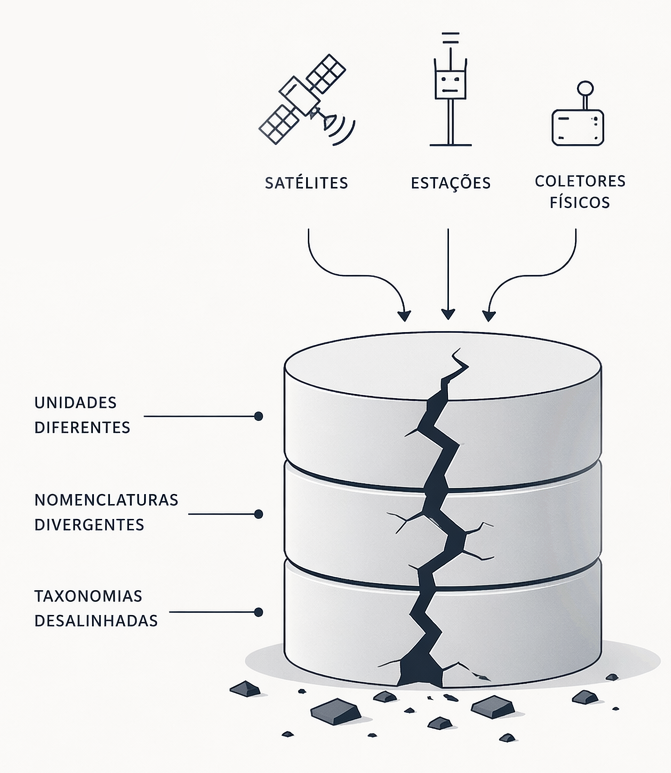
La percepción de que existía un problema crítico en la forma en que se trataban los datos científicos surgió directamente de la práctica. Actuando como investigador independiente y especialista invitado en proyectos como CAIPORA, percibí que la pluralidad de información buscada por los grupos — procedente de satélites, recolectores físicos y estaciones — se presentaba en formatos completamente distintos. Incluso con una lógica de agrupación organizada, no quedaba tiempo para que las personas se detuvieran a normalizar esos datos; las unidades no coincidían y las taxonomías eran divergentes.
Sin una gobernanza dedicada a este proceso, entendí que el proyecto ya nacía con una inconsistencia en la información básica, lo que llamo comenzar el trabajo sobre una “base agrietada”. Fue esta brecha la que me motivó a estructurar DataShipper, actuando en frentes que tratan y normalizan datos para facilitar su uso por parte del equipo académico, garantizando que esta metodología genere escalabilidad en diferentes tecnologías y ecosistemas.
A continuación, presento un análisis de los desafíos enfrentados y de cómo DataShipper busca resolverlos.
1. La identificación de la “base agrietada” al inicio de la investigación
El primer gran desafío de la ciencia moderna es la fragmentación de las fuentes. En proyectos de gran escala, cada científico asume la responsabilidad de su especialidad, pero la ausencia de una gobernanza centralizada hace que la normalización sea descuidada. El resultado es una base de información fundamentalmente problemática incluso antes del inicio del desarrollo científico.
Lo que realmente marca la diferencia para un proyecto que busca alcance académico y social no es solo la organización básica, sino una lógica de normalización que conecte estos datos con el mundo real. Dentro del abanico de servicios y frentes de DataShipper, trabajamos para que esta normalización sea el cimiento que permita al equipo académico centrarse en lo que importa, garantizando la integridad de la investigación desde el origen.
2. El “salto de fe”: los obstáculos computacionales y cognitivos

La transición del dato bruto a una solución concreta enfrenta barreras severas, comenzando por el desafío computacional de procesar y almacenar terabytes de información. Sumado a eso, existe el límite cognitivo de interpretar datos brutos sin interfaces que los traduzcan de manera eficiente.
Esta dificultad empuja al cuerpo académico hacia una validación basada solo en muestras o “fragmentos”, lo que da lugar a un peligroso “salto de fe”. Es importante destacar que, aunque el método científico garantice la integridad del resultado final, estos pequeños “saltos de fe” no son más que la decisión de seguir adelante con el riesgo latente de tener que rehacer el trabajo. La ausencia de una sistemática universal obliga al investigador a trabajar durante meses para descubrir solo después, a partir de un resultado inesperado, que la información inicial no era precisa. DataShipper busca precisamente sustituir ese riesgo por la capacidad de garantizar de antemano la integridad de los datos.
3. El dolor de la coordinación y el riesgo del retrabajo
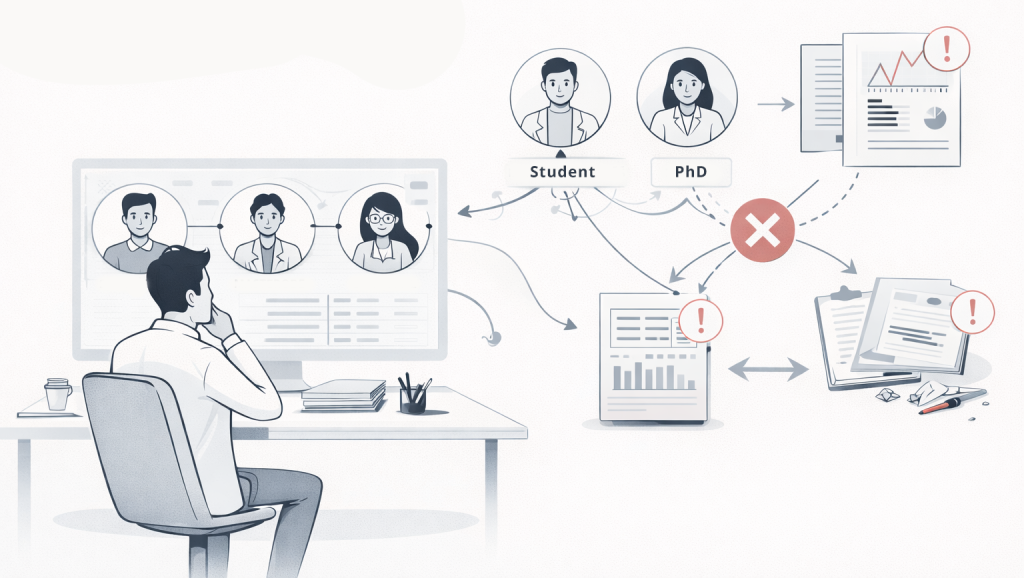
En el nivel de gestión, el coordinador académico enfrenta el desafío de equilibrar calidad y velocidad mientras gestiona equipos heterogéneos, tanto desde el aspecto multidisciplinario como por el hecho de que algunos proyectos incluyen desde becarios de iniciación científica hasta doctorados experimentados. Validar lo que cada científico aporta al proyecto exige lidiar con datos brutos para comprender su integridad, una tarea agotadora que muchas veces lleva al retrabajo. Existe la sensación de que la parte fundamental del liderazgo, que es promover la evolución del conocimiento del grupo, compite con trivialidades que terminan adquiriendo una magnitud mayor.
Como uno de sus frentes de apoyo a la coordinación, DataShipper garantiza la integridad y la normalización de los datos como una premisa del proyecto. Esto se realiza mediante soluciones inteligentes (como la “Data Bridge”) y una metodología de integración y onboarding de los investigadores. Este enfoque elimina la preocupación sobre la funcionalidad del dato y evita que errores descubiertos demasiado tarde comprometan el proyecto. Al asegurar que las entregas del equipo estén integradas entre sí, aumentamos la confianza en el equipo y reducimos la inseguridad del coordinador en cuanto a la integridad de la metodología científica aplicada.
4. Actuar en la raíz del problema: el diferencial de DataShipper

La esencia de nuestra actuación es lidiar con la radicalidad de los problemas. Entendemos que si una inconsistencia obliga al investigador a volver atrás y rehacer el trabajo, la falla no reside en el descubrimiento científico, sino en la sistematización y consistencia de esos datos.
Uno de los frentes fundamentales de DataShipper es crear mecanismos capaces de mantener estos datos organizados y estandarizados, devolviendo la confianza necesaria al equipo académico. Nuestra metodología garantiza que los datos se distribuyan de forma normalizada y se inserten en tecnologías escalables, permitiendo un consumo dinámico, productivo y humanizado. Esto asegura que la investigación pueda evolucionar a largo plazo, conectándose con otros ecosistemas. Trabajando en paralelo con el equipo del proyecto, garantizamos que el dato recorra su camino con integridad hasta llegar al punto final para la sociedad, generando una diferencia real.

